Abstract
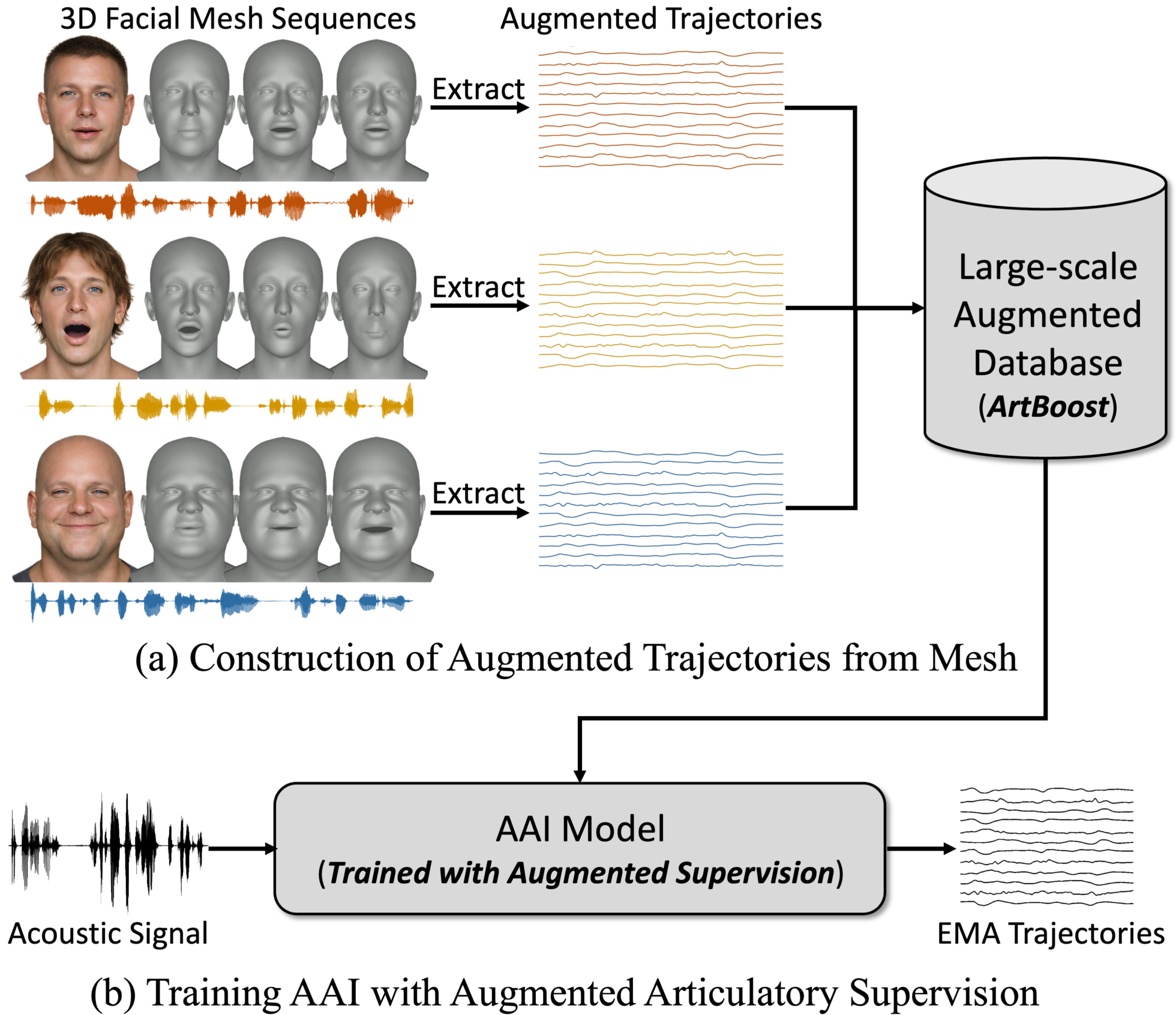
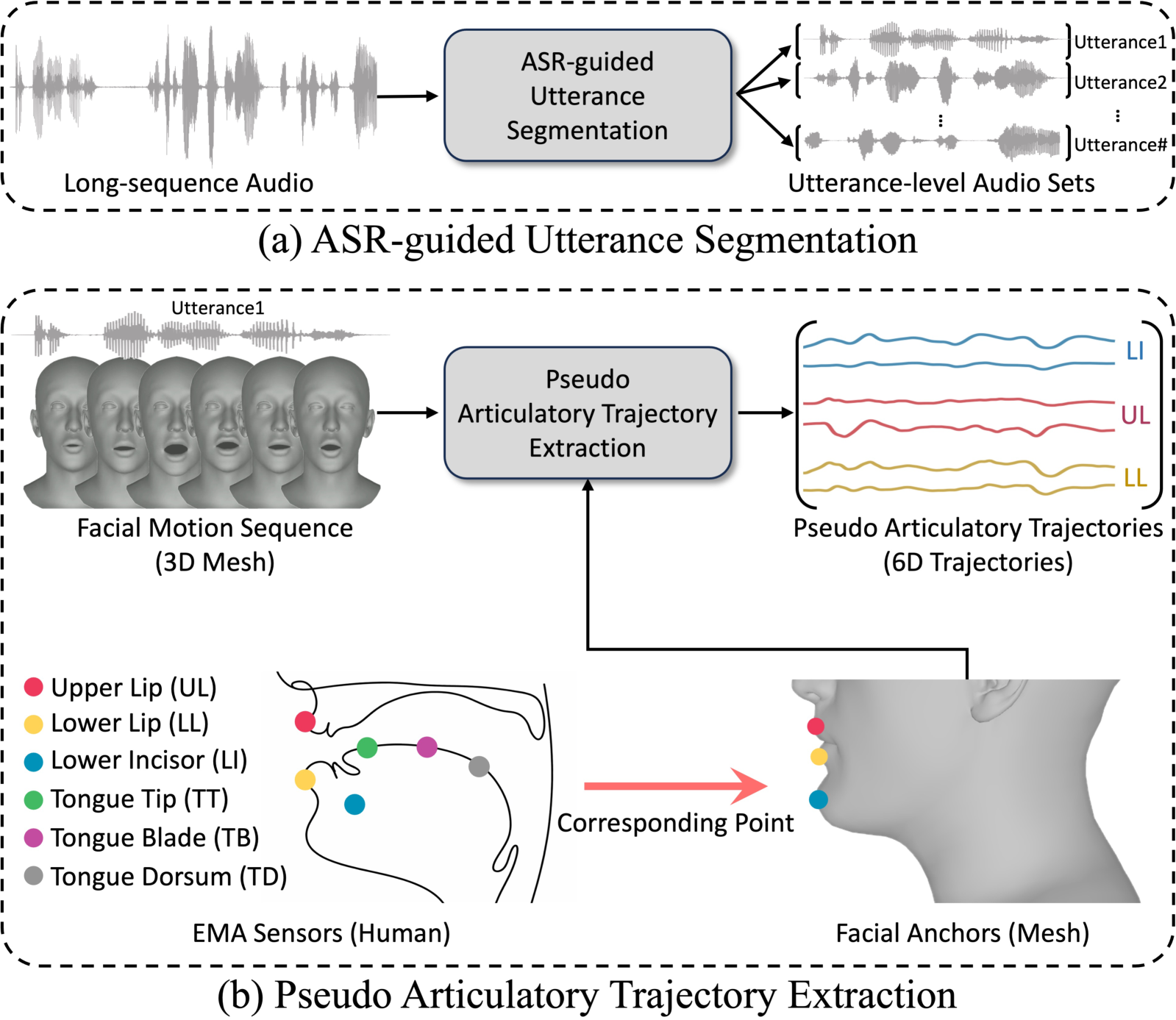
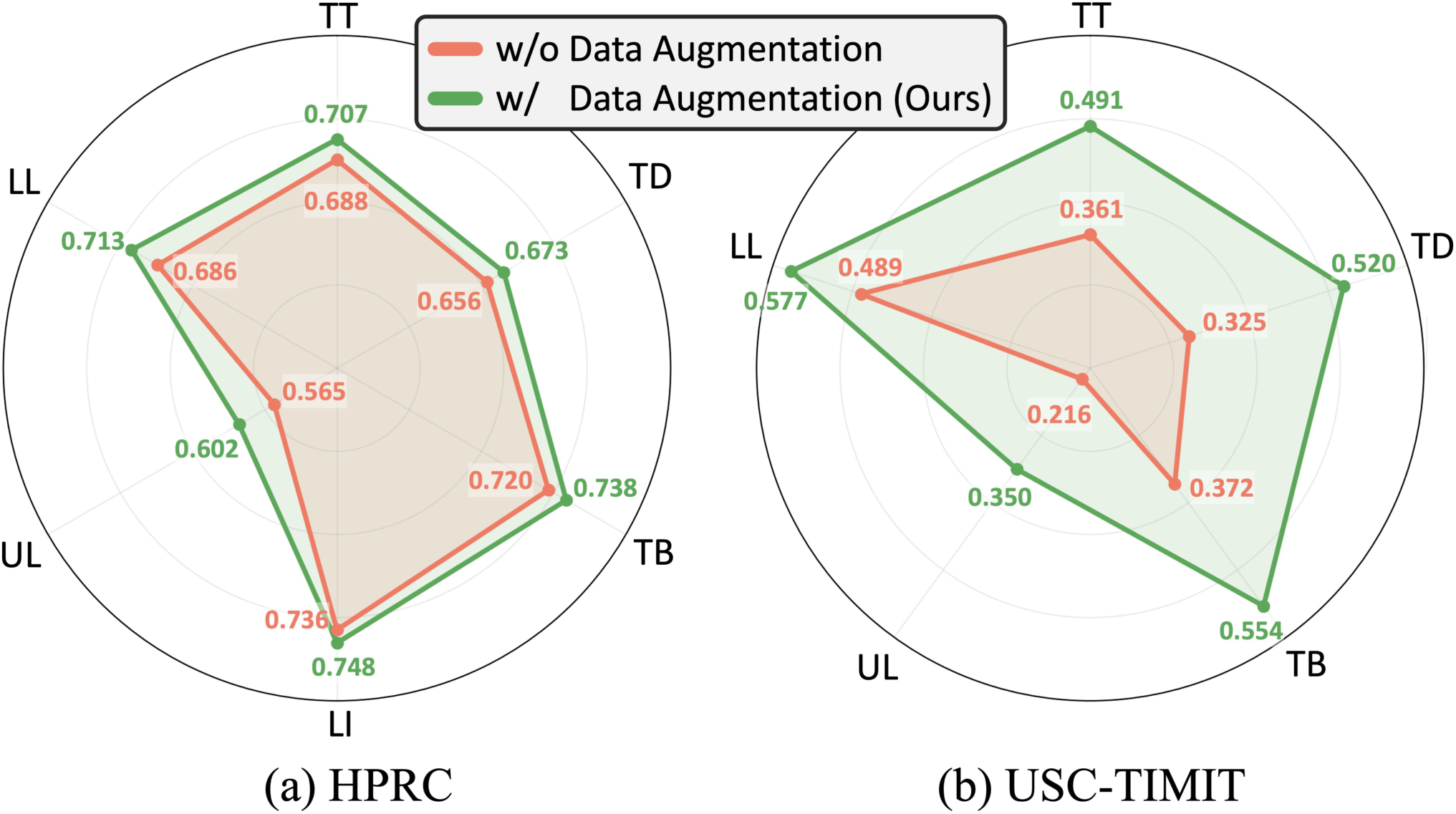
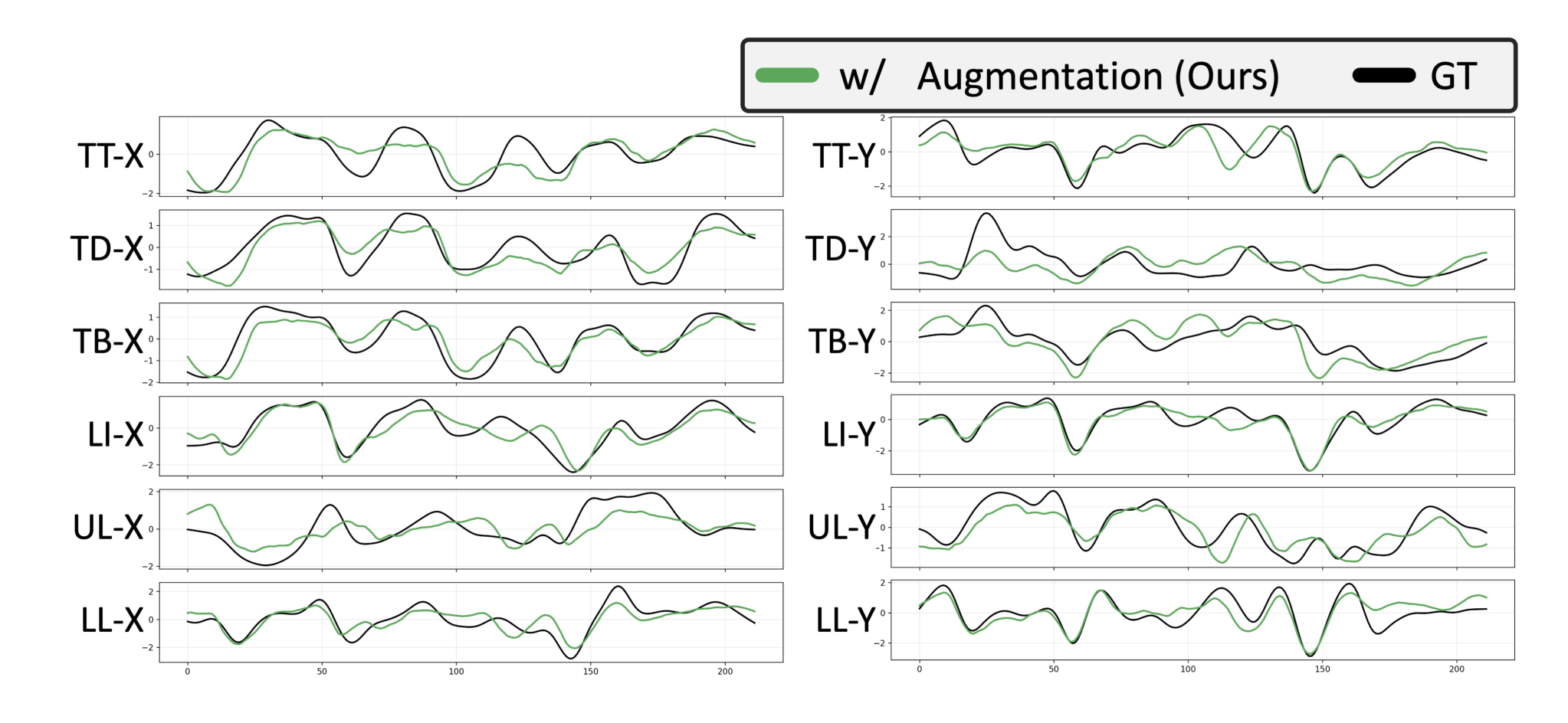
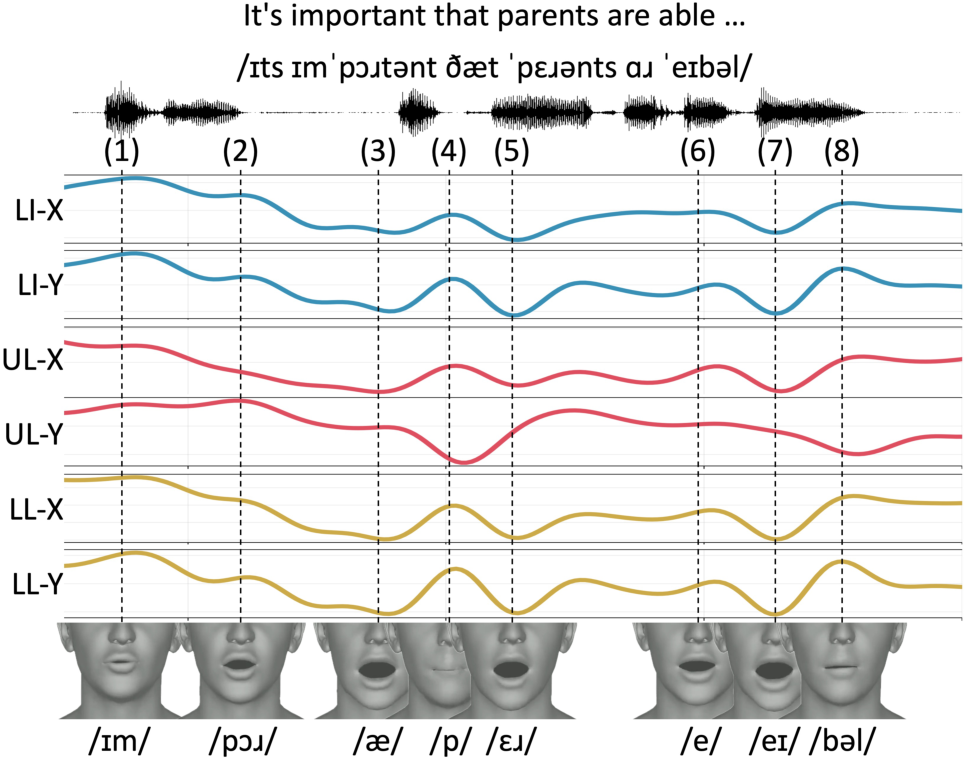
Recent acoustic-to-articulatory inversion (AAI) models rely on electromagnetic articulography (EMA) data, which are costly and limited in scale. To address this limitation, we propose ArtBoost, a novel data augmentation strategy that leverages large-scale speech–mesh datasets originally developed for speech-driven 3D facial animation to improve AAI under limited EMA supervision. ArtBoost extracts pseudo articulatory trajectories from visible facial anchors and uses them for pre-training before fine-tuning on real EMA data. Experiments show consistent improvements in PCC and RMSE. Trajectory analyses confirm that the pseudo articulatory signals reflect physically meaningful visible articulatory dynamics. Additional evaluations across different AAI architectures demonstrate stable performance gains, indicating that ArtBoost can be integrated into diverse AAI models. These results suggest that speech–mesh data provide an effective and scalable source of articulatory supervision for AAI.